ROI von Produktdatenqualität – Vorgehen im Projekt (Teil 2)

Um die Rendite verbesserter Datenqualität berechnen zu können, bedarf es zunächst einiger vorbereitender Maßnahmen. Begonnen wird im Allgemeinen mit einer subjektiven sowie objektiven Datenanalyse. Der subjektive Teil besteht aus einer Befragung verschiedener Spezialisten aus den entsprechenden Fachbereichen. Diese haben tagtäglich mit „ihren“ Daten zu tun und wissen daher, wo die Probleme liegen. Doch Vorsicht, sehr oft kommen bei solchen Interviews nur Symptome zur Sprache, die eigentliche Ursache der Datenqualitäts-Probleme liegt häufig woanders. Denn Fachbereichsverantwortliche kennen logischerweise ihren Fachbereich am besten. Wenn es beispielsweise ein Problem im Entstehungsprozess der Daten im Warenwirtschaftssystem gibt, kann das auch Auswirkungen auf die Qualität des Webshops haben. Es wäre aber ineffizient und meist teurer dieses am Ende des Prozesses, im Webshop, zu lösen (siehe 1-10-100-Regel aus Teil 1).
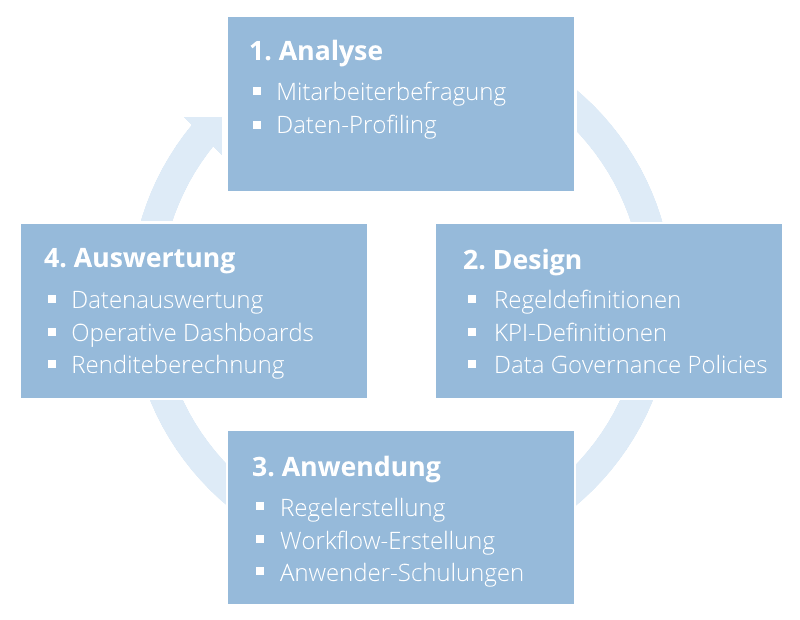
Wurden die größten Schwachpunkte identifiziert, beginnt die objektive Datenanalyse anhand der Verwendung verschiedener Profiling-Techniken. Diese beginnt bei einfachem Spalten-Profiling, also dem Auslesen von Datenmustern aus einzelnen Datenbank-Spalten, und kann bis zum unternehmensweiten sog. „Data Domain Discovery“ reichen. Dazu wird eine semantische Analyse der Daten durchgeführt und es können dabei besonders schützenswerte „Data Domains“ (z.B. personenbezogene Daten) daraufhin untersucht werden, ob sie in unerwünschten Systembereichen auftreten und ein Sicherheitsrisiko darstellen.
Nach der Analysephase beginnt die Definition von Regeln zur Verbesserung der Daten- und Prozessqualität. DQ-Regeln sollten zunächst auf fachlicher Ebene definiert werden, z.B.: welches Datenfeld muss an welcher Stelle im Prozess welchen Kriterien entsprechen? Dabei können verschiedene Qualitätsstufen definiert werden, etwa eine „Muss“- und eine „Kann“-Datenqualität. Ist die Muss-Stufe nicht erreicht, werden Datensätze im entsprechenden Prozessschritt zurückgehalten und müssen nachgepflegt werden. Zusätzlich zu den Qualitätsregeln sollten KPIs, also betriebswirtschaftliche Kennzahlen, definiert werden, die voraussichtlich durch die Regeln positiv beeinflusst werden. Eine sehr häufig anzutreffende KPI im Bereich der Produktdaten ist der sog. Time-to-Market Index und beschreibt die durchschnittliche Zeit, die ein Produktdatensatz von seiner Anlage bis zur Veröffentlichung in einem Verkaufssystem benötigt. Wird diese KPI zu Beginn eines DQ-Projektes gemessen, und wird im Rahmen des Projekts eine Effizienzsteigerung im Anlage- und Pflegeprozess von Produktdaten angestrebt, kann diese später als Indikator für den Projekterfolg dienen.
In der Anwendungsphase werden die zuvor definierten Regeln nach und nach ausgerollt. Es finden Anwender-Schulungen statt, die zumindest wichtige Key User mit den neuen Tools und Prozessen vertraut machen sollten. Es lohnt sich hier eine gut verständliche und umfangreiche Systemdokumentation zu verfassen, damit diese auch zu einem späteren Zeitpunkt die zentrale Anlaufstelle für aufkommende Fragen darstellt.
Parallel zur Anwendungsphase oder spätestens wenn sich die neuen Prozesse einigermaßen eingespielt haben, kann die Auswertung der verbesserten Datenqualität beginnen. Hierfür werden am besten Dashboards mit einer übersichtlichen und grafisch ansprechenden Darstellung verwendet. Eines der führenden Tools im Bereich DQ-Management, Informatica Data Quality, bietet Möglichkeiten zur visuellen Repräsentation der historischen Entwicklung der Datenqualität aufgeteilt in die verschiedenen Dimensionen mitsamt Kostenindikation:
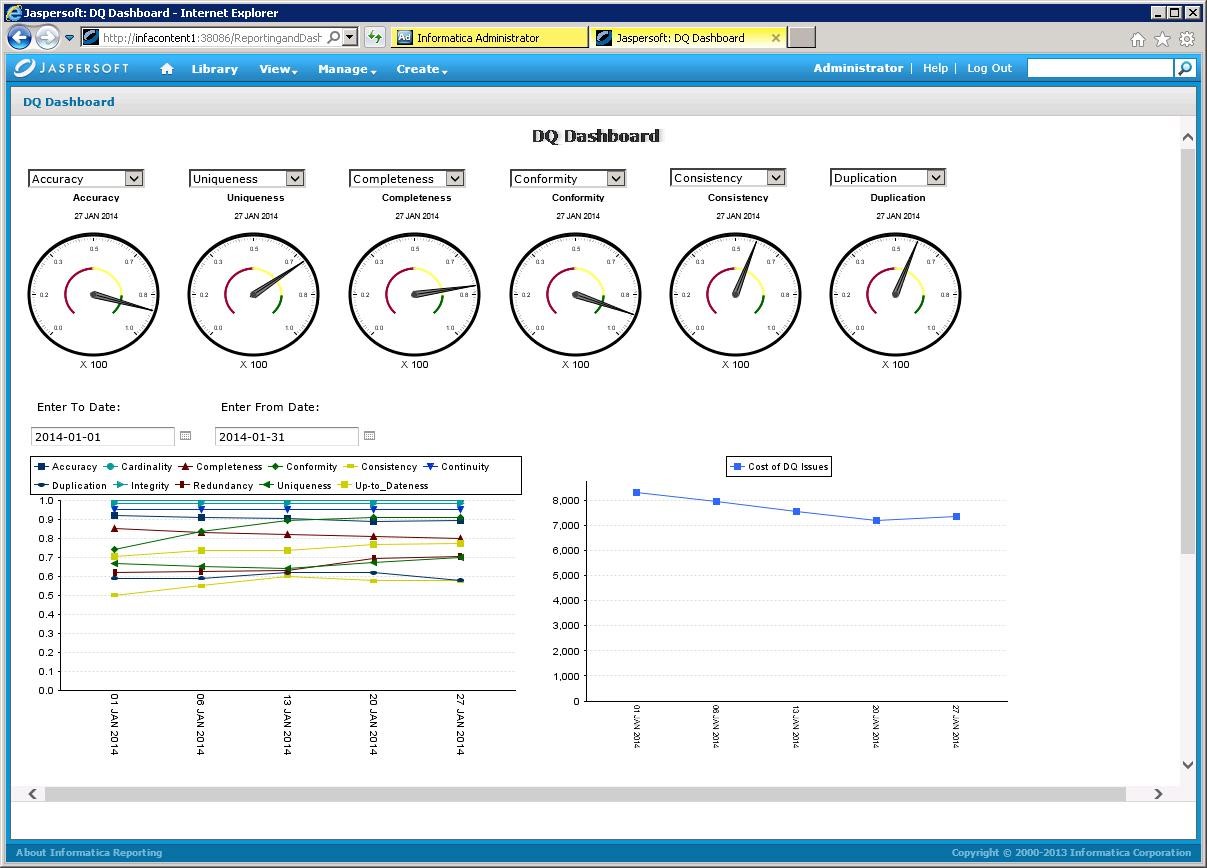
Quelle: https://marketplace.informatica.com/solutions/data_quality_dashboards_and_reporting_961
Solch ein Dashboard ist nicht nur interessant für Datenverantwortliche, sondern ermöglicht auch die oben beschriebene Vorgehensweise mit einem iterativen Projektvorgehen zu verknüpfen und damit eine schrittweise Verbesserung der Datenqualität zu erreichen. Es wurde dabei bewusst auf Empfehlungen zur Länge der einzelnen Phasen verzichtet, da sich diese je nach Projektkontext von wenigen Tagen bis über mehrere Wochen oder Monate erstrecken können.
Im nächsten Teil dieser Reihe werden die eigentliche Renditeberechnung eines DQ-Projekts thematisiert und dabei Methoden der dynamischen Investitionsrechnung vorgestellt, um letztendlich zu einer nachvollziehbaren und seriösen Kosten-Nutzen-Analyse zu gelangen.
>> ROI von Produktdatenqualität – Anwendung der dynamischen Investitionsrechnung
Autor: Christoph Koch und Technical Consultant
Lesen Sie auch die anderen Teile der Artikel-Serie:
Teil 1: ROI von Produktdatenqualität – Theoretische Grundlagen
Teil 3: ROI von Produktdatenqualität – Anwendung der dynamischen Investitionsrechnung