Measuring the ROI of Product Data Quality (part 1)

We live in the Information Age, an age characterized mainly by an increasing digitalization and exponential data growth. If we are to believe a well-known American market intelligence company, the amount of data being generated annually will grow to 44 zettabytes by 2020 (IDC, 2014). This is about ten times more than in 2013 and corresponds to the staggering amount of 44 billion 1 TB hard disks. We certainly notice that, in our everyday life, more and more devices are equipped with sensors and probably our refrigerators will soon be able to automatically detect when to order new groceries.
This incredible amount of data will need a more efficient data management – not only on an individual level. More and more companies are appointing a CDO (Chief Data Officer) to drive overall data management strategy, implement enterprise-wide data standards and set up data governance initiatives. This central role is supposed to help firms to harness today’s flood of available data and to protect sensitive information from prying eyes.
Quite often we are asked, at parsionate, to advise our customers on how to efficiently manage data. The 1-10-100 rule (Chang, 1994) has proved quite useful when illustrating the consequences of poor data quality standards. The rule states that it costs much less to fix a problem when data is created or entered by the user (preventive action) than at later stages. It will cost the business 10 times the initial outlay if a data record is cleansed and corrected during a quality check (with additional effort) after submission. Modifying data when it has already been transferred to the target system is the most expensive option. Just imagine the consequences of displaying wrong or misleading information about a product: your customers will probably send back the product immediately.
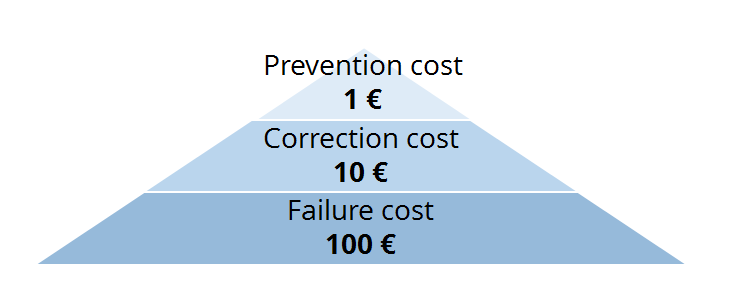
Thus, data checks should be performed at the beginning of your data collection chain and inaccurate information should be corrected immediately. It’s cheaper and will ensure that all target systems have the same data quality. Let’s have a closer look at the term “Data Quality” (DQ). The following is a definition frequently found in the literature: Data are of high quality “if they are fit for their intended uses in operations, decision making and planning.” (Juran, 1951). The principle of “fitness and usability” of data entails the main goal of DQ improvement: it’s not about providing the best conceivable data quality, but about ensuring that it is the most appropriate for the application. For example, it won’t make sense to link an elaborately formatted rich text including images to a product record if there is no target system that is able to display the given format and, worse still, if the text becomes unreadable because of specific control characters.
But what does this “fitness for use” imply in terms of data quality? The most commonly metrics used to assess the quality of data are the so-called DQ dimensions.
The following data quality dimensions are usually considered:

Thus, for example, it will not suffice to use an article’s expiration date, stored in the ERP system as mandatory field, in order to control visibility of the article in the web shop (completeness). It must also be ensured that this information is stored in a suitable format for the web shop (conformity). Otherwise, for example, the day could be interpreted as month and vice versa, thus resulting in inaccurate or even invalid (if day > 12) information (accuracy).
Apart from the six technical dimensions, process quality is a key issue in any DQ project. Process quality usually depends on a company’s organisation and its associated roles and responsibilities for the various data domains. Due to the increasingly complex data structures in medium to large enterprises, a centralized data governance body should be set up, comprising experts from different departments who will decide upon data models, data ownership and data maintenance processes. Establishing such a body is a long term task and is far more expensive than the technical improvements based on DQ dimensions. Nonetheless, it will effectively and sustainably improve data quality processes – a fact that should be taken into account since DQ is getting a more and more important issue.
Our next part will focus on parsionate’s general approach to DQ projects – a precondition in order to be able to measure the ROI of product data quality.
>> ”Measuring the ROI of Product Data Quality – Project approach (part 2)”
Read the other parts of this article series as well:
Part 2: Measuring the ROI of Product Data Quality – Project Approach
Part 3: Measuring the ROI of Product Data Quality – Dynamic Investment Appraisal